Highlights from Virta Ventures’ Climate x AI Panel
By
Virta Ventures
ON
April 30, 2024

On April 24th during SF Climate Week, the Virta team and Silicon Valley Bank hosted 40 founders, funders, operators, and climate tech enthusiasts in the SVB Experience Center. Over lunch, Russell Sprole (Founder and GP of Virta Ventures), Michael Baker (Co-Founder and CEO of Tyba), Emma Fuller (Co-Founder of Fractal Agriculture), and Shaurya Saluja (Co-Founder and CEO of Fleet) discussed intersections between AI and the climate tech space and how climate tech startups are leveraging the latest AI advances in their core products, business operations, and more.
Huge thanks to our speakers and attendees for an interesting and productive conversation. We’re excited to share our takeaways with you.
Lesson 1: Finding AI’s Power in Underdigitized Realms
While our panelists lead companies in diverse industries (energy, agriculture, and mobility), what unites their domain areas is one common challenge: underdigitization. Operating within these underdigitized industries, panelists shared similar stories of overcoming operational roadblocks like lack of access to digitized data, issues with data quality and structure, and limited technical fluency and aptitude among customers and users. During our discussion, our panelists shared how AI holds unprecedented power in allowing startups to overcome these hurdles as digital disruptors.
Lesson 2: Recognizing AI-Driven Impacts on Climate
Also top-of-mind was AI development’s potential carbon footprint and climate impact. There was consensus that we need to make sure that, as we scale up AI development, we keep AI progress and climate progress aligned.
A key piece of that puzzle is ensuring that AI hardware runs on renewable energy. Tyba noted an increase in activity by their customers (renewable energy and storage developers) driven entirely by new AI-related data center new construction and expansion. This is a fortuitous signal that AI-driven energy demand increases may be met by clean supply, at least in the U.S.
Lesson 3: Finding The “Right” Data to Fuel AI Development
In an ideal world, startups are able to find the exact dataset they need to train models and build products.
However, in underdigitized domains like the ones our panelists operate in, startups face the following challenges in data access:
- Relevant datasets may be incomplete and / or lack crucial information – an example shared by Shaurya (Fleet) is how Caltrain (the SF Bay Area commuter rail service) has a dataset for all rides on their service, but doesn’t have the variables in the dataset needed to observe where riders disembark the trains.
- Relevant datasets might not exist in a digital format, or might not exist altogether. Emma from Fractal discussed how farmland sales are tracked in binders and file cabinets, not spreadsheets.
- Relevant datasets might be held by government entities or incumbent players like electric utility companies who are either unwilling or unable to share, as Tyba experiences in the energy sector.
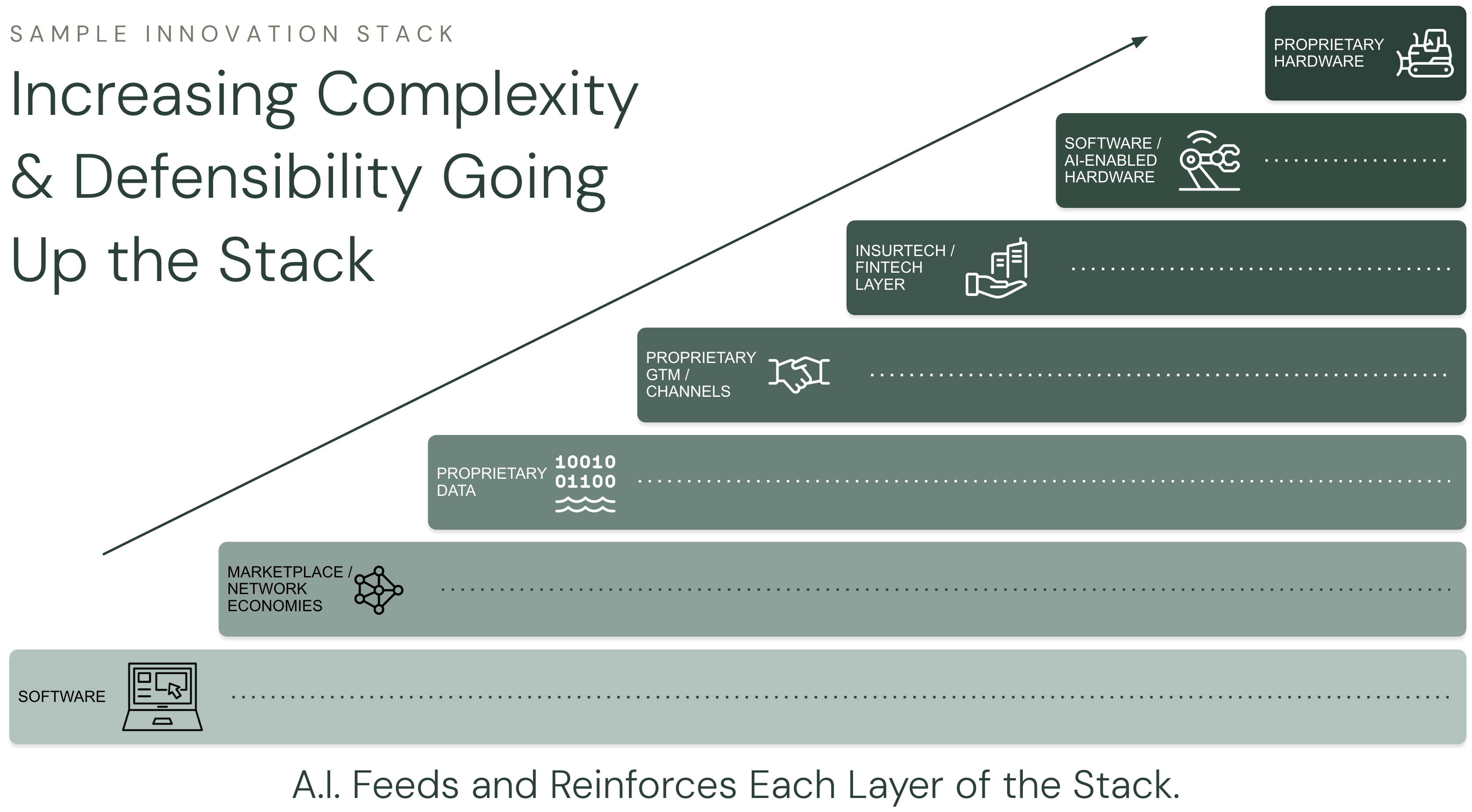
Startups hoping to provide AI-powered data insights in underdigitized domains need to find ways to deliver despite these data access issues, and successfully overcoming these challenges can become its own moat.
In choosing between data sources in an imperfect data world, Emma (Fractal) noted the importance of identifying data sources by potential advantage driven and potential data reliability. For instance, Emma shared that Fractal de-emphasizes public datasets and opts to work directly with farms to generate proprietary aggregated datasets for agriculture. This approach ensures data reliability by going to the end source, while also setting the foundation for a long-term data moat.
Lesson 4: Bridging the AI Gap for Non-Technical Stakeholders
Our panelists discussed how, in underdigitized industries like energy / agriculture / mobility, AI can help bridge the gap between data and business insights for non-technical stakeholders.
One key use case of AI bridging the gap is in the automated creation of digestible data visualizations for easy customer consumption. Michael (Tyba) noted that, in his experience working with Tyba customers, non-technical / non-data-oriented stakeholders often still struggled to digest visualization outputs. To address this, Michael shared that Tyba goes one step further, using generative AI to annotate Tyba’s data dashboards to ensure comprehension for their users.
Emma (Fractal) shared how, in the relationship-driven agriculture industry, Fractal found that they needed a “human touch” in their operations and data delivery to reduce friction and maximize trust. Paradoxically, Emma noted, Fractal’s “human touch” became a differentiator due to the recent democratization of AI-driven insights.
Lesson 5: Securing Defensibility When AI Alone Isn’t a Strong Moat
During our conversation, our panelists shared how characteristics of AI systems can differentiate startups in the climate tech space – for instance, building moats in their AI operations through proprietary datasets for unique insights and lasting advantage. Shaurya (Fleet) shared how he is developing a proprietary dataset and understanding of how people move, building Fleet’s moat of holding mobility data that even transportation companies do not have a full view of.
They also spoke to how startups can layer additional points of differentiation on top of AI technology to build further defensibility. Michael (Tyba) underscored the importance of having a strong product and go-to-market strategy on top of AI technology, and shared how Tyba furthers its AI advantage by applying real-world energy domain expertise to make AI insights more useful and relevant for their stakeholders. The motivation behind Tyba’s product strategy, Michael noted, is to build a platform that provides value propositions beyond the underlying AI technology that resonate with customers and users.
Lesson 6: Building a Future-Proofed Team for AI Development
It’s clear from our conversation that AI has transformed how startup teams grow and operate at scale. Our panelists noted that, with AI developments, they need less headcount to operate, so they are very critical when thinking about potential hires. Emma (Fractal) shared that they would be building a team of 4+ data scientists just a few years ago and now can get much further with only 2 data scientists. Shaurya (Fleet) highlighted that a great software engineer could be a 20-30X engineer with the added leverage of copilots, versus just a 10X engineer a few years ago.
Our panelists also noted that roles are changing within their companies with the advent of AI. While pre-AI more technical tasks like SQL querying were owned by specific point people, AI democratizes these functions, allowing individuals to move faster with more autonomy.
A huge thank you to Michael, Emma, and Shaurya for sharing their insights – as well as to everyone who joined us in-person for lunch. We’ll be sharing more insights at the intersection between AI and climate, deep-diving into some of the topics we covered live, and introducing new insights on the AI x Climate space. Be sure to subscribe to our Substack to get our latest insights straight in your inbox.